ARTICLE AD BOX
Alibaba's Qwen team just added two new members to its Qwen2.5 family: Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M.
These open-source models can work with context windows of up to one million tokens, making them the first publicly available models with such long context windows.
The models use sparse attention, focusing only on the most important parts of the context. This approach processes million-token inputs three to seven times faster than traditional methods, with outputs up to 8,000 tokens long. However, this requires the models to identify crucial passages in context documents - a task that current language models often struggle with.
In testing, both the 14B model and Qwen2.5-Turbo achieved perfect accuracy when finding hidden numbers in very long documents. The smaller 7B model also performed well, with only minor errors. However, these benchmarks mainly test information retrieval - similar to a costly Ctrl+F - rather than deeper understanding of content.
Ad
THE DECODER Newsletter
The most important AI news straight to your inbox.
✓ Weekly
✓ Free
✓ Cancel at any time
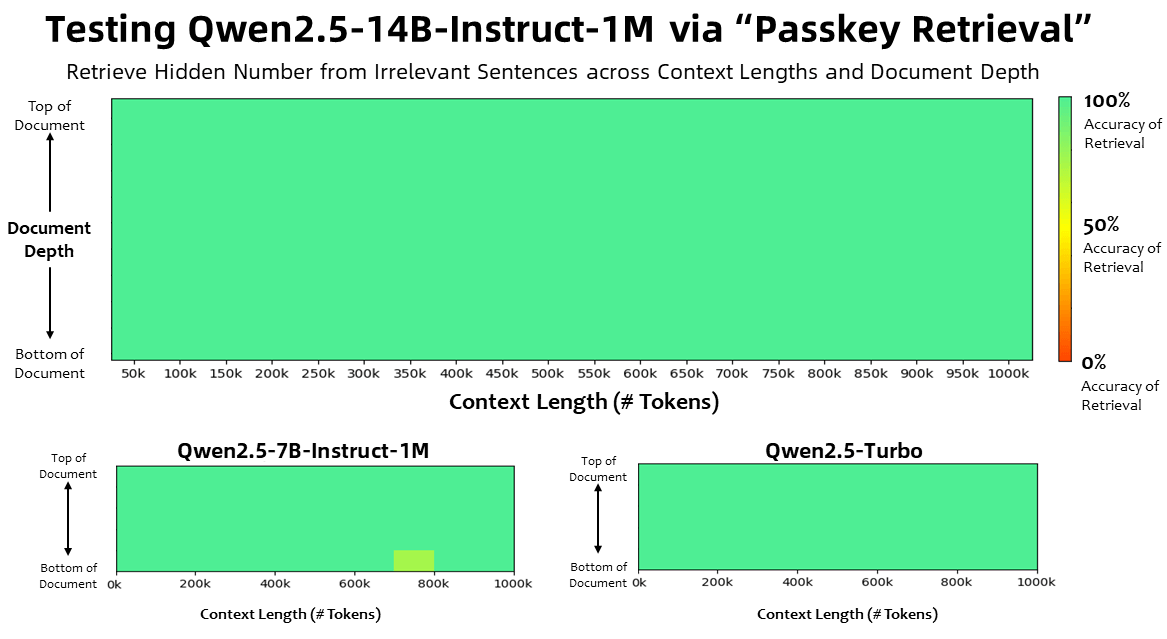 The test results show the accuracy of different Qwen2.5 models in retrieving information from long documents. The 256K token training version achieves similarly accurate results as models with longer context windows. | Image: Qwen
The test results show the accuracy of different Qwen2.5 models in retrieving information from long documents. The 256K token training version achieves similarly accurate results as models with longer context windows. | Image: QwenThe advantages of large context windows over RAG systems are not straightforward. Long context windows are easier to use and more flexible, but RAG architectures, which pull information from external databases during inference, often work more precisely and effectively with much smaller context windows of about 128,000 tokens
Complex context testing shows promising results
In more demanding tests like RULER, LV-Eval and LongbenchChat, the million-token models outperformed their 128K counterparts, especially with sequences longer than 64K tokens. The 14B model even scored above 90 points in RULER - a first for the Qwen series - consistently beating GPT-4o mini across multiple datasets.
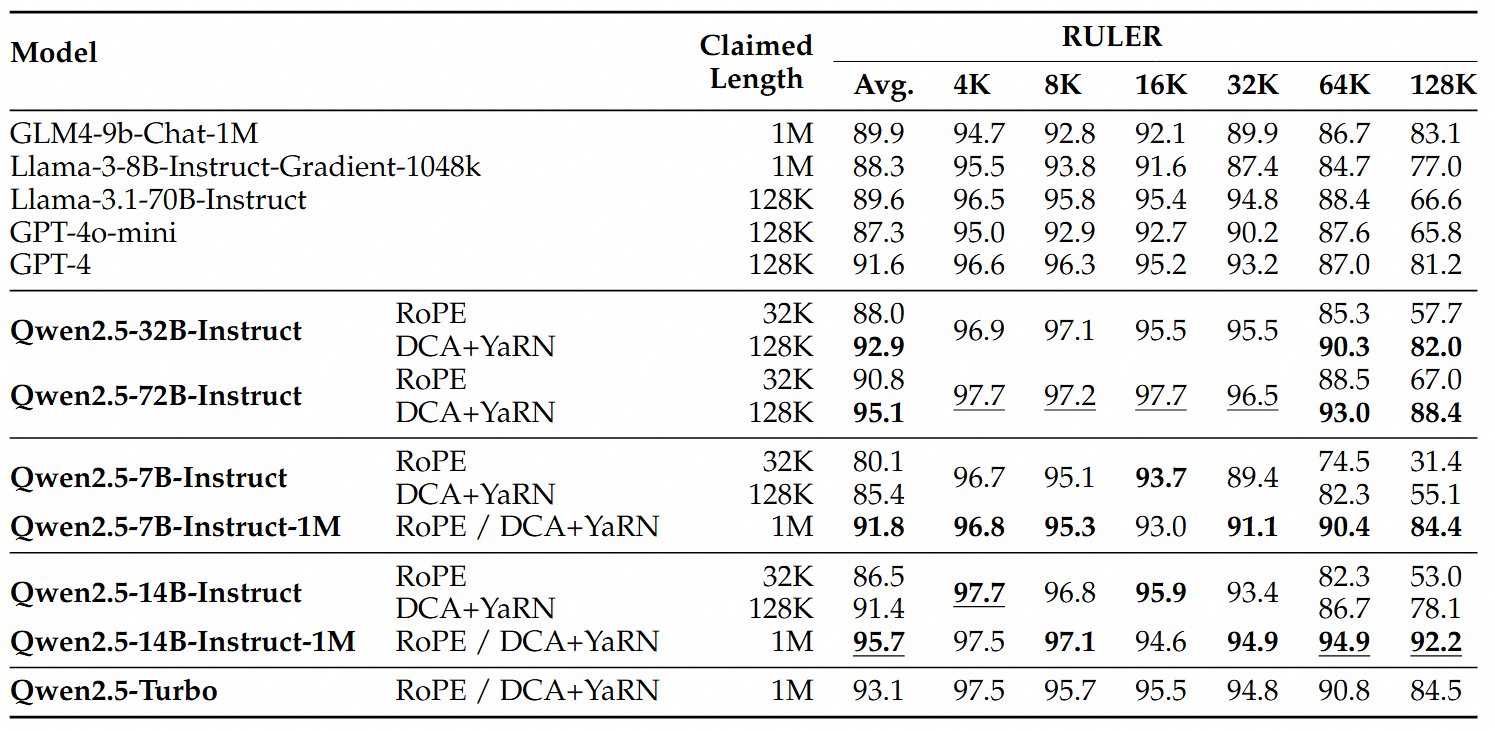 The Qwen2.5 models show good performance in the RULER benchmark, especially on longer sequences. | Image: Qwen
The Qwen2.5 models show good performance in the RULER benchmark, especially on longer sequences. | Image: QwenFor shorter texts, the million-token models matched the performance of their 128K counterparts, showing no trade-offs in handling brief content.
Users can try this and other Alibaba models through Qwen Chat, Alibaba's ChatGPT-like interface, or through a demo on Hugging Face. Along with fellow Chinese company Deepseek's open-source models, Qwen is challenging established U.S. providers by offering similar capabilities at lower costs.
