ARTICLE AD BOX
Researchers at TikTok parent company ByteDance have presented OmniHuman-1, a new framework for generating videos from image and audio samples.
The new system from TikTok's parent company turns still images into videos by adding movement and speech. A demonstration shows Nvidia CEO Jensen Huang appearing to sing, highlighting both the system's capabilities and potential risks.
ByteDance researchers developed OmniHuman-1 to solve a key challenge in AI video generation: creating natural human movements at scale. Previous systems struggled when given more training data, since much of it contained irrelevant information that had to be filtered out, often losing valuable movement patterns in the process.
To address this, OmniHuman processes multiple types of input simultaneously - text, image, audio, and body poses. This approach allows the system to use more of its training data effectively. The researchers fed it about 19,000 hours of video material to learn from.
Ad
THE DECODER Newsletter
The most important AI news straight to your inbox.
✓ Weekly
✓ Free
✓ Cancel at any time
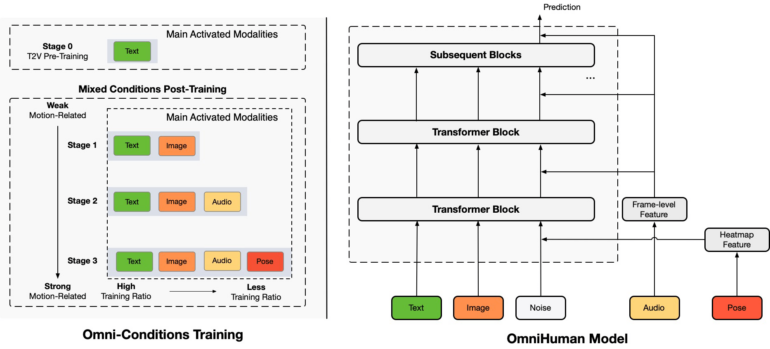 The OmniHuman framework combines a DiT-based model with a multi-stage training strategy. The architecture processes text, image, audio and pose data in parallel, while the training takes into account the complexity of the movement information. | Image: ByteDance
The OmniHuman framework combines a DiT-based model with a multi-stage training strategy. The architecture processes text, image, audio and pose data in parallel, while the training takes into account the complexity of the movement information. | Image: ByteDanceThe system first processes each input type separately, compressing movement information from text descriptions, reference images, audio signals, and movement data into a compact format. It then gradually refines this into realistic video output, learning to generate smooth motion by comparing its results with real videos.
 OmniHuman generates high-quality animations for a wide range of input formats, from portraits to full-body shots. | Image: ByteDance
OmniHuman generates high-quality animations for a wide range of input formats, from portraits to full-body shots. | Image: ByteDanceThe results show natural mouth movements and gestures that match the spoken content well. The system handles body proportions and environments better than previous models, the team reports.
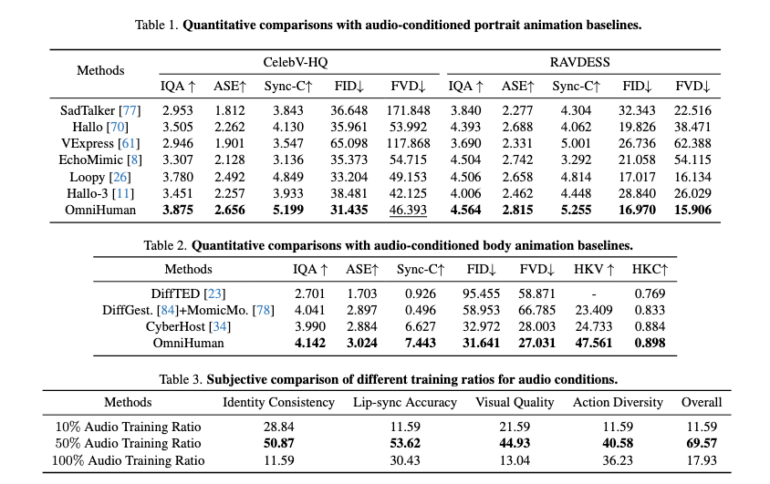 In almost all quality and realism tests, OmniHuman-1 clearly outperforms previous methods. | Image: ByteDance
In almost all quality and realism tests, OmniHuman-1 clearly outperforms previous methods. | Image: ByteDanceBeyond photos of real people, the system can also animate cartoon characters effectively.
Video: ByteDance
Theoretically unlimited AI videos
The length of generated videos isn't limited by the model itself, but by available memory. The project page shows examples ranging from five to 25 seconds.
Recommendation

This release follows ByteDance's recent introduction of INFP, a similar project focused on animating faces in conversations. With TikTok and video editor CapCut reaching massive user bases, ByteDance already implements AI features at scale. The company announced plans to focus heavily on AI development in February 2024.
