ARTICLE AD BOX
Seed Diffusion Preview is Bytedance's experimental AI model for code generation, designed to generate tokens in parallel instead of one at a time. The company says it can reach speeds of 2,146 tokens per second on Nvidia H20 GPUs.
Seed Diffusion Preview uses a "discrete-state diffusion" approach. While diffusion models are usually built for continuous data like images, Bytedance has adapted the method for discrete data such as text and code.
Instead of generating each token in sequence, the model reconstructs code from a noisy, placeholder-filled state. Multiple sections of code are generated at once, thanks to a transformer architecture that enables parallel prediction, not just the standard step-by-step process.
This parallel workflow leads to much faster generation, but according to Bytedance, code quality remains high. In benchmark tests, Seed Diffusion Preview performed competitively with other models, and stood out especially for code editing tasks.
Ad
THE DECODER Newsletter
The most important AI news straight to your inbox.
✓ Weekly
✓ Free
✓ Cancel at any time
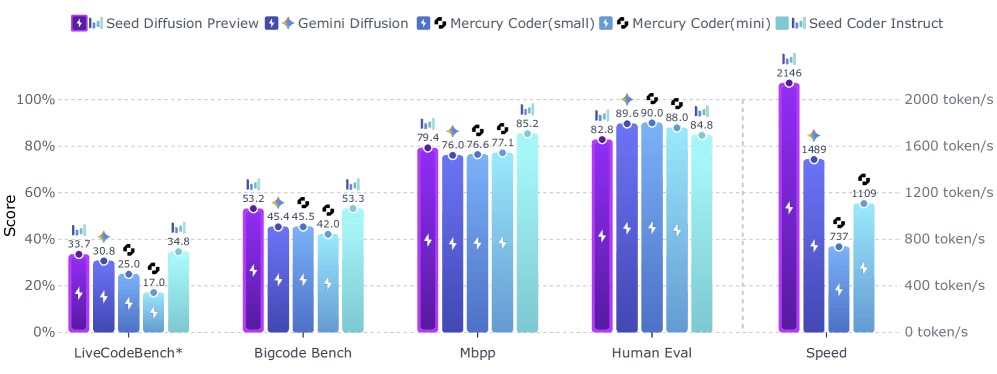 eed Diffusion delivers the fastest inference speeds and can match or outperform autoregressive and diffusion-based competitors. | Image: Bytedance
eed Diffusion delivers the fastest inference speeds and can match or outperform autoregressive and diffusion-based competitors. | Image: BytedanceTo address problems in standard masked diffusion models, Bytedance uses a two-stage training process. The first stage relies on mask-based training, replacing parts of the code with special placeholder tokens.
But this can sometimes make the model copy unmasked tokens without really checking them. To fix this, the team added a second phase: edit-based training with insertions and deletions. This forces the model to review and correct all tokens, not just the masked ones.
The team also optimized the generation order, taking code structure and dependencies into account - for example, making sure variables are declared before they're used. They then trained the model on a large, filtered dataset of high-quality generation sequences created by the pre-trained model itself.
Self-optimizing parallel decoding
While diffusion models should, in theory, enable parallel decoding, actually achieving this is complicated. Each parallel inference step is computationally demanding, and reducing the number of steps can hurt quality.
Bytedance tackled this by training the model to optimize its own generation process using "on-policy learning." The goal is to minimize the number of steps, while a verification model checks output quality.
Recommendation

For practical use, Seed Diffusion Preview processes code in parallel within blocks, but keeps a logical order between the blocks. The team also tweaked its software stack for diffusion processes, using an internal framework built for this kind of workload.
Seed Diffusion Preview is Bytedance’s answer to Google’s Gemini Diffusion, which was announced in May and also targets code generation. Bytedance says it plans to keep experimenting with scaling and adapting the approach for more complex reasoning tasks. There’s a demo available here.
