ARTICLE AD BOX
Chinese AI company Deepseek has built an OCR system that compresses image-based text documents for language models, aiming to let AI handle much longer contexts without running into memory limits.
The main idea is that processing text as an image can use less compute than working with the digital text itself. According to Deepseek's technical paper, their OCR can compress text by up to a factor of ten while keeping 97 percent of the original information.
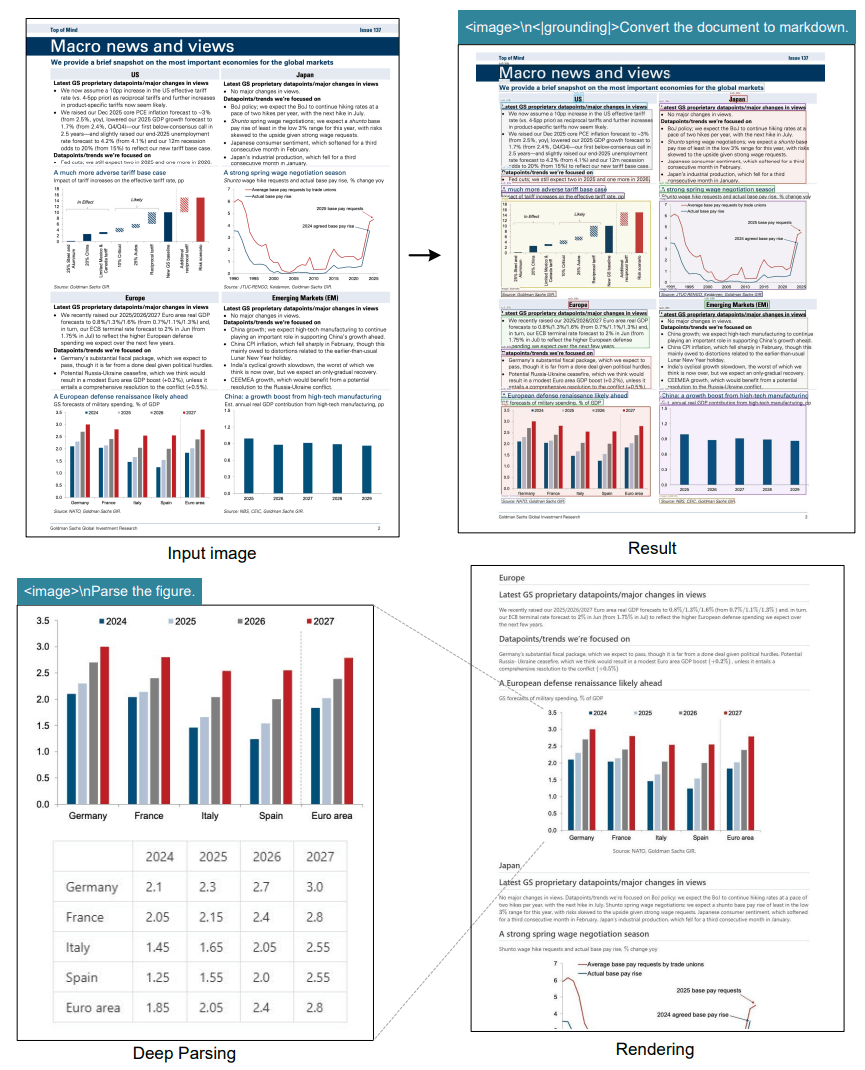
Deepseek OCR's deep parsing mode can convert financial charts into structured data, automatically generating Markdown tables and graphs. | Image: DeepseekThe system has two core parts: DeepEncoder, which handles image processing, and a text generator built on Deepseek3B-MoE with 570 million active parameters. DeepEncoder itself uses 380 million parameters to analyze each image and produce a compressed version.
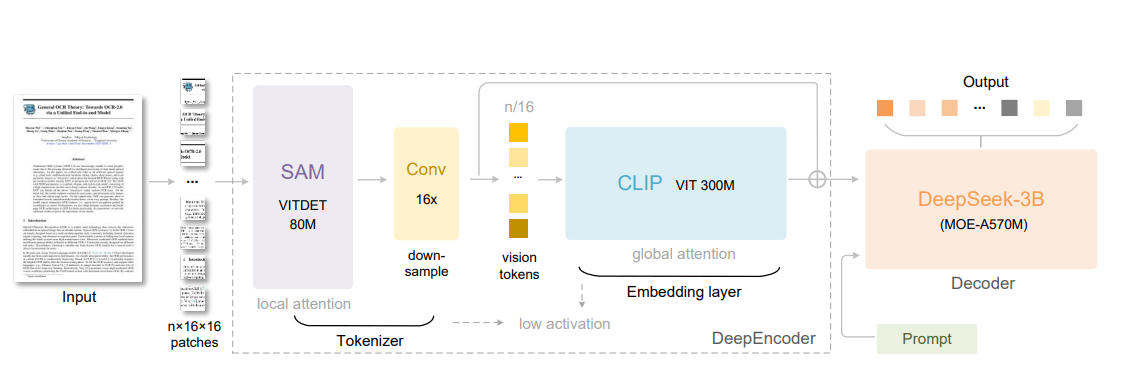 Deepseek OCR brings together local image analysis from SAM-ViTDet and global context from CLIP ViT-300M, using a 16x token compressor before Deepseek 3B-MoE decodes the recognized text. | Image: Deepseek
Deepseek OCR brings together local image analysis from SAM-ViTDet and global context from CLIP ViT-300M, using a 16x token compressor before Deepseek 3B-MoE decodes the recognized text. | Image: DeepseekDeepEncoder joins Meta's 80-million-parameter SAM (Segment Anything Model) for image segmentation with OpenAI's 300-million-parameter CLIP, which links images and text. A 16x compressor sits between them, drastically cutting the number of image tokens. A 1,024 by 1,024 pixel image starts with 4,096 tokens. SAM processes them, and the compressor reduces this to just 256 tokens, which are then passed to the compute-intensive CLIP model.
Ad
THE DECODER Newsletter
The most important AI news straight to your inbox.
✓ Weekly
✓ Free
✓ Cancel at any time
Deepseek OCR can work with a range of image resolutions. At lower resolutions, it needs only 64 "vision tokens" per image; at higher resolutions, up to 400. By comparison, conventional OCR systems often require thousands of tokens for the same task.
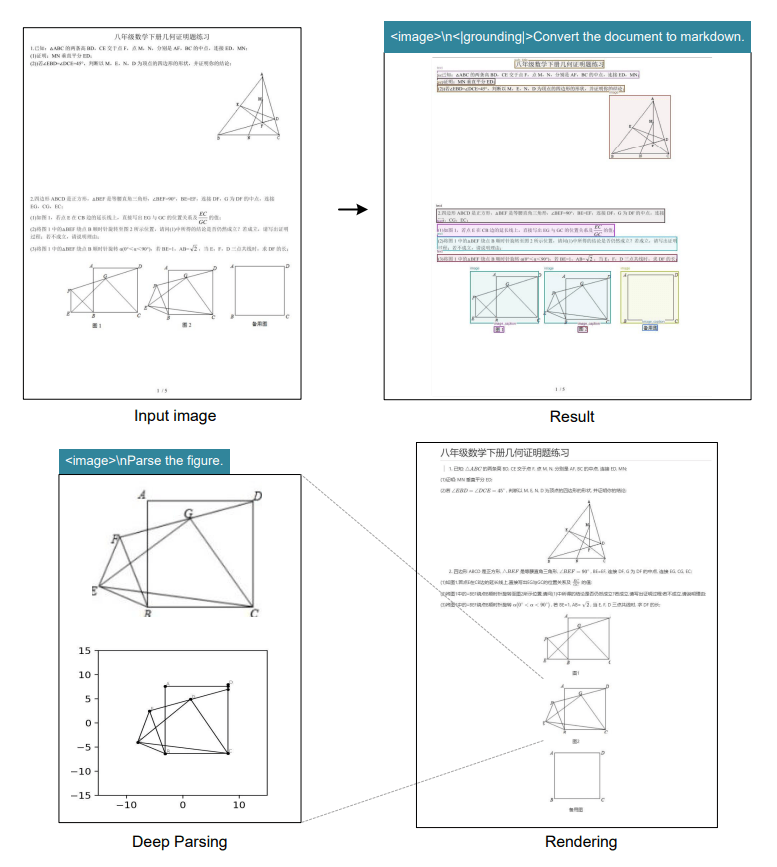 Parsing even simple vector graphics is still a challenge for Deepseek OCR. | Image: Deepseek
Parsing even simple vector graphics is still a challenge for Deepseek OCR. | Image: DeepseekIn OmniDocBench tests, Deepseek OCR outperformed GOT-OCR 2.0 using just 100 vision tokens compared to 256. With fewer than 800 tokens, it also beat MinerU 2.0, which requires more than 6,000 tokens per page.
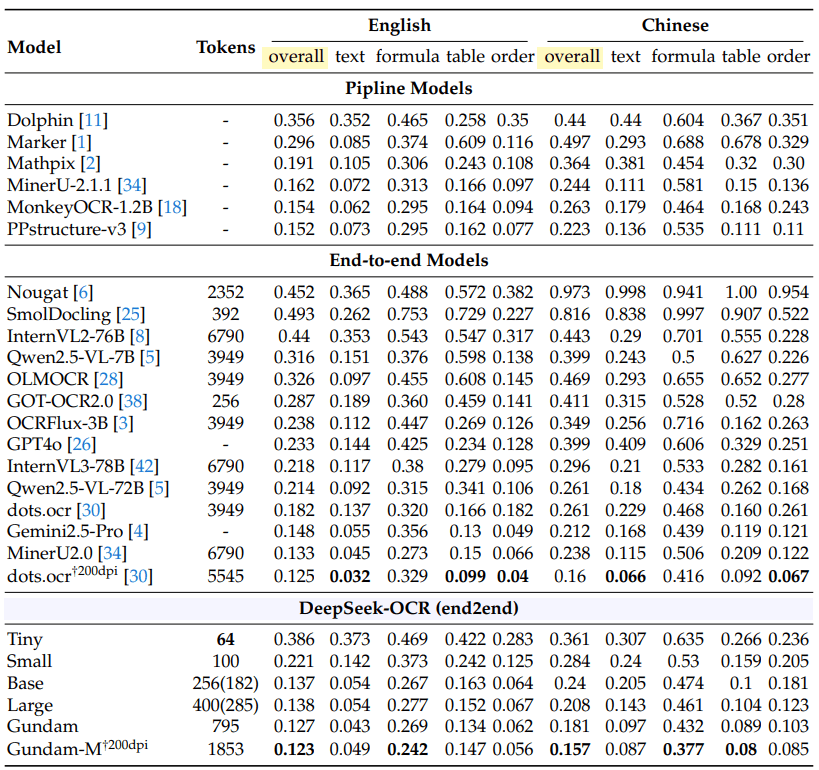 On OmniDocBench, Deepseek OCR goes head-to-head with dots.ocr from Xiaohongshu and Rednote. | Image: Deepseek
On OmniDocBench, Deepseek OCR goes head-to-head with dots.ocr from Xiaohongshu and Rednote. | Image: DeepseekToken requirements depend on the document. Simple presentations use 64 tokens. Books and reports need about 100. Complex newspapers require Deepseek's "Gundam mode" with up to 800 tokens.
 Deepseek OCR adjusts compression rates and token counts with scaling, padding, and multi-page or sliding window methods for better efficiency and accuracy. | Image: Deepseek
Deepseek OCR adjusts compression rates and token counts with scaling, padding, and multi-page or sliding window methods for better efficiency and accuracy. | Image: DeepseekThe system supports a wide range of document types, from plain text to diagrams, chemical formulas, and geometric figures. It works in about 100 languages, can keep the original formatting, output plain text, and still provide general image descriptions.
For training, the researchers used 30 million PDF pages in roughly 100 languages, including 25 million in Chinese and English, along with 10 million synthetic diagrams, 5 million chemical formulas, and 1 million geometric figures.
Recommendation
Processes 33 million pages per day
In real-world use, Deepseek OCR can process over 200,000 pages per day on a single Nvidia A100 GPU. With 20 servers, each running eight A100s, throughput jumps to 33 million pages daily.
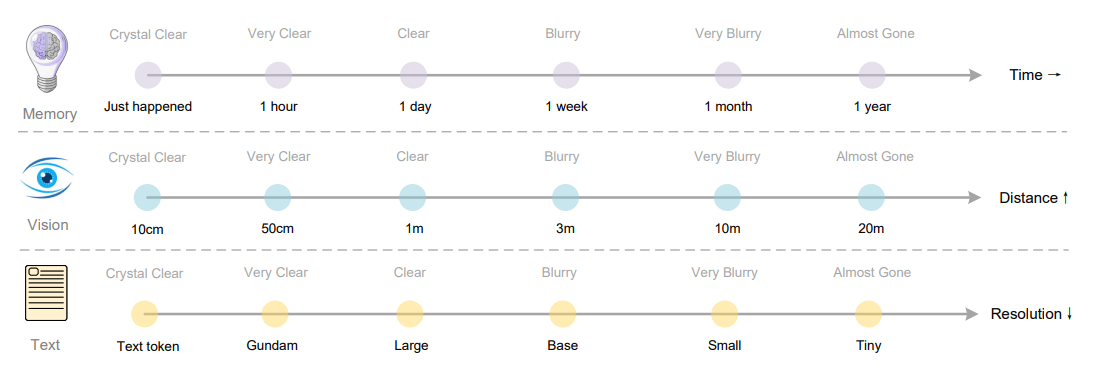 The researchers propose using Deepseek OCR to compress chatbot conversation histories, storing older exchanges at lower resolution—similar to how human memory fades—so AI can handle longer contexts without a spike in compute costs. | Image: Deepseek
The researchers propose using Deepseek OCR to compress chatbot conversation histories, storing older exchanges at lower resolution—similar to how human memory fades—so AI can handle longer contexts without a spike in compute costs. | Image: DeepseekThis kind of throughput could help build training datasets for other AI models. Modern language models need massive amounts of text, and Deepseek OCR can extract it from documents. Both the code and model weights are publicly available.


