ARTICLE AD BOX
A new study finds that humans can read analog clocks with 89.1 percent accuracy, but the best AI model only manages 13.3 percent. The results highlight a major gap in visual reasoning for current language models.
Alek Safar put 11 large language models from six companies head-to-head with five humans using a new test called ClockBench. The benchmark includes 180 custom analog clocks and 720 questions, following the "easy for humans, hard for AI" approach seen in benchmarks like ARC-AGI and SimpleBench.
To keep things fair and avoid overlap with training data, Safar built the dataset from scratch. There are 36 unique clock face designs mixing Roman and Arabic numerals, different orientations, hour markers, mirrored layouts, and colorful backgrounds. He made five different clocks for each design, for a total of 180 clocks.
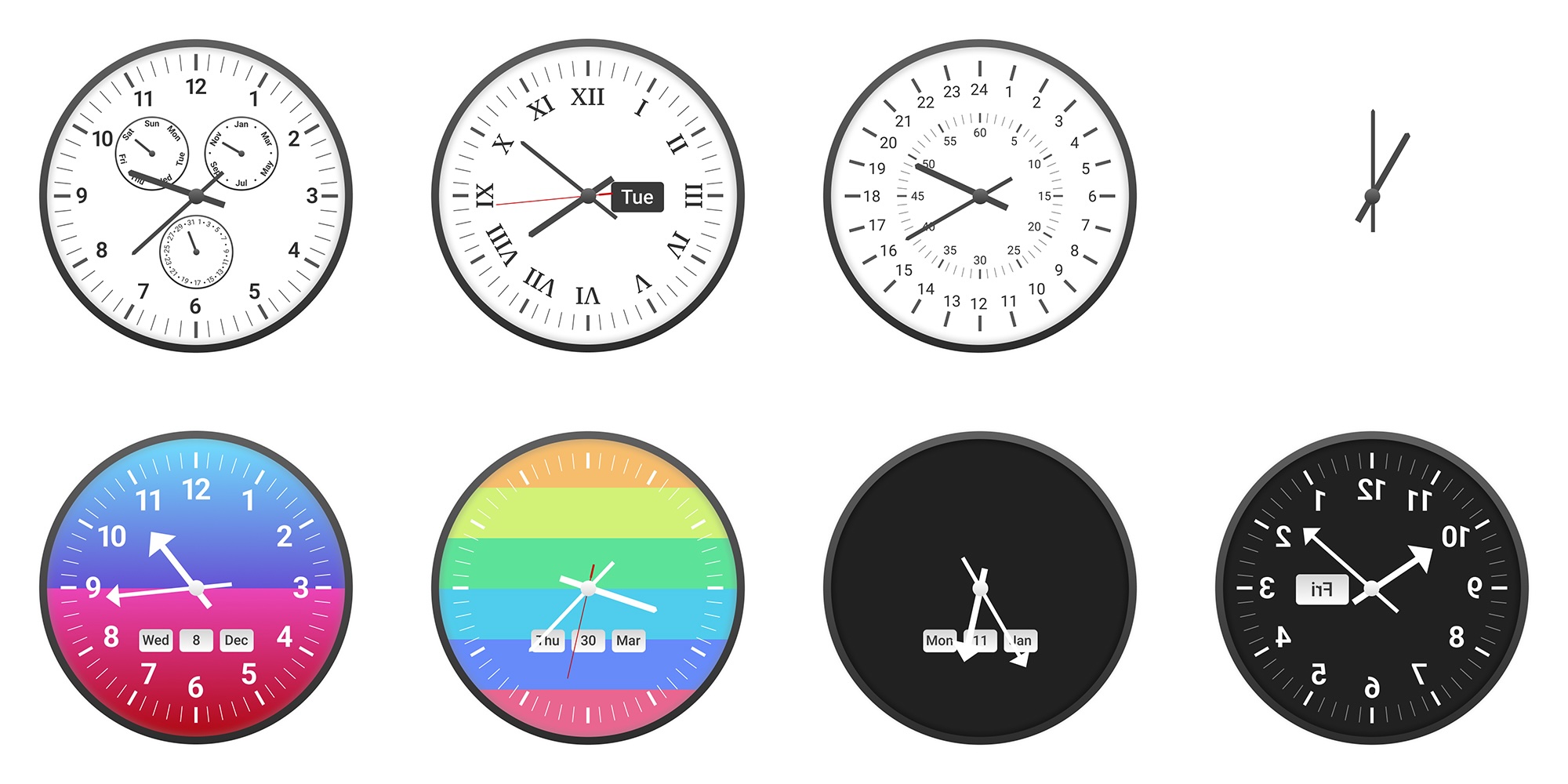 Eight sample clock designs from the private ClockBench dataset show the range of dials, formats, numerals, and calendar features. | Image: Alek Safar
Eight sample clock designs from the private ClockBench dataset show the range of dials, formats, numerals, and calendar features. | Image: Alek SafarEach clock was tested with four types of questions: reading the time, doing time calculations, shifting hands by specific angles, and converting time zones. Safar allowed different levels of error depending on the clock. For example, clocks with only an hour hand had bigger margins for error than those with all three hands.
Ad
THE DECODER Newsletter
The most important AI news straight to your inbox.
✓ Weekly
✓ Free
✓ Cancel at any time
Safar says ClockBench is tougher for AI models than knowledge-heavy tests like "Humanity's Last Exam." The results show just how far AI still lags behind humans on what looks like a simple visual task.
Google leads, but all models struggle
Google’s Gemini 2.5 Pro posted the highest score at 13.3 percent, with Gemini 2.5 Flash close behind at 10.5 percent. GPT-5 came in third at 8.4 percent, and tweaking the models’ reasoning budgets didn’t help much.
Grok 4 landed at the bottom with just 0.7 percent accuracy, which is surprising since it often does well in other benchmarks. Grok 4 marked 63.3 percent of clocks as invalid, even though only 37 out of 180 clocks actually showed impossible times. This ultra-cautious approach meant Grok 4 technically had the most correct answers, but only by randomly flagging clocks as invalid.
Anthropic’s Claude 4 Sonnet (4.2 percent) and Claude 4.1 Opus (5.6 percent) didn’t do much better. The study also found that 61.7 percent of clocks were not read correctly by any single model.
Error sizes tell the real story
The size of the mistakes was even more revealing than the accuracy rates. Humans made a median error of just 3 minutes. The best AI model missed by a median of one hour. The weakest models were off by around three hours - about as good as guessing at random for a 12-hour clock.
Recommendation

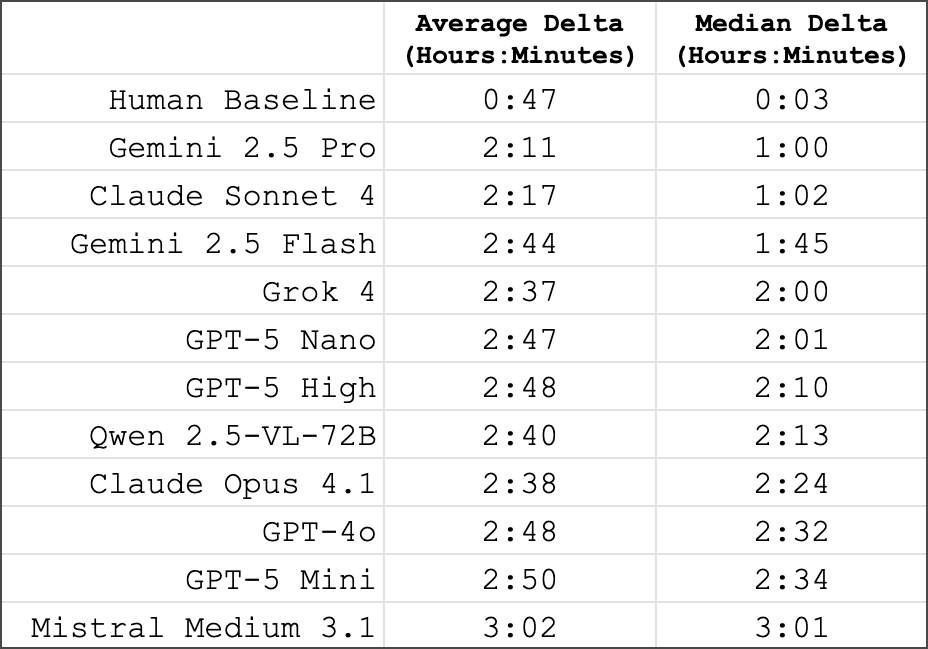 Humans have a median error of 3 minutes when reading analog clocks. For AI, the median error ranges from 1 to over 3 hours. | Image: Alek Safar
Humans have a median error of 3 minutes when reading analog clocks. For AI, the median error ranges from 1 to over 3 hours. | Image: Alek SafarSome clock features were especially tough for AI. Accuracy dropped to 3.2 percent with Roman numerals, and 4.5 percent with circular numerals. Second hands, colorful backgrounds, and mirrored layouts also caused trouble.
Clocks with only an hour hand were easiest for AI (23.6 percent accuracy), since bigger errors were allowed. Standard clocks with Arabic numerals and basic dials also led to better results.
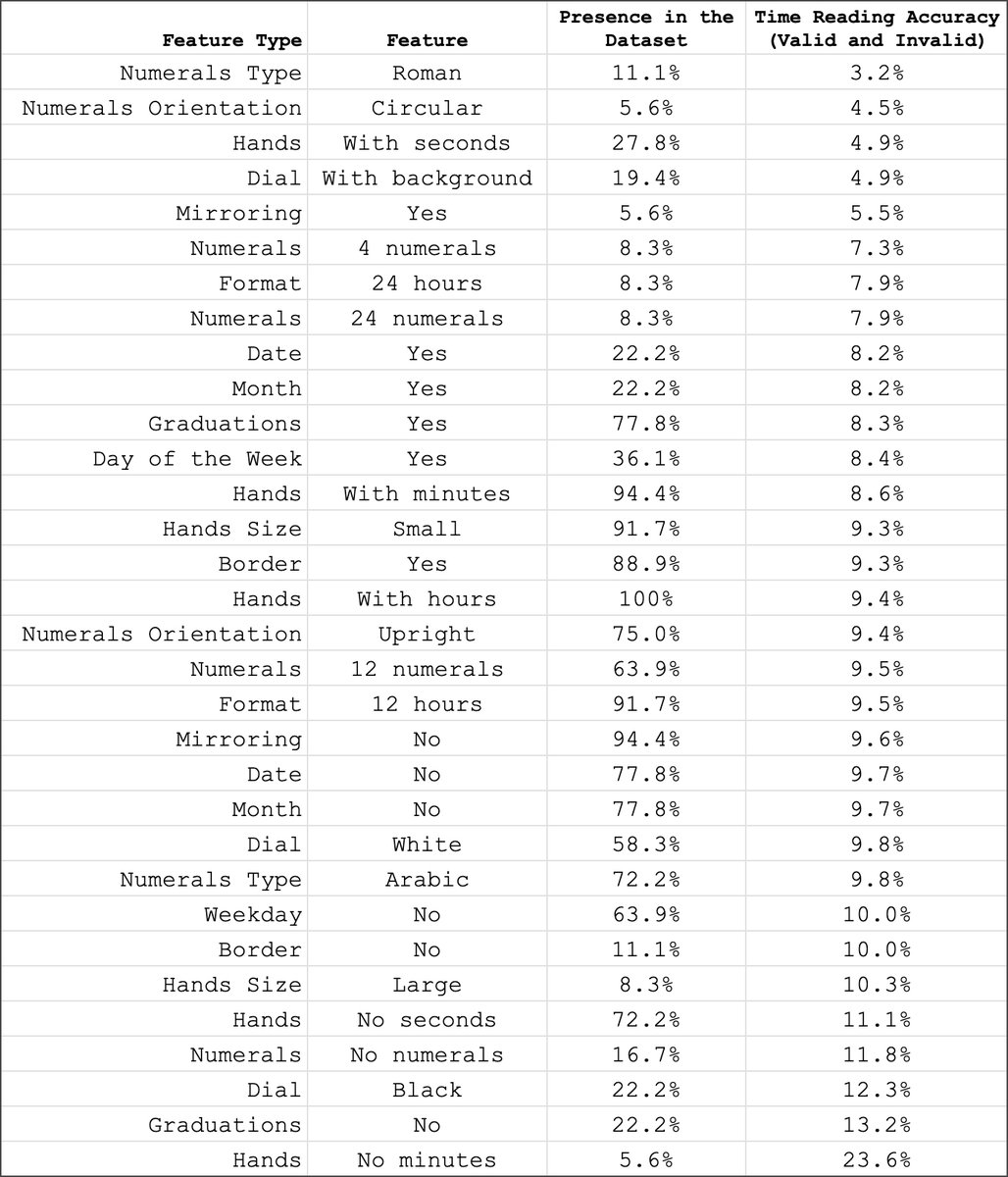 Different dial features change how well models can read the time. | Image: Alek Safar
Different dial features change how well models can read the time. | Image: Alek SafarAI can do the math, but can’t read the clock
There was one surprise: when models managed to read the time correctly, they almost always got time calculations, hand shifts, or time zone conversions right. So the challenge isn’t doing math with time; it's reading the visual information to begin with.
Safar thinks there could be a few reasons for this. Reading analog clocks might be a tough test for visual reasoning. Rare or unusual clock designs probably don’t show up much in training data, and turning a visual clock face into a text description is likely a challenge for these models.
ClockBench aims to push AI forward
ClockBench is set up as a long-term benchmark. The full dataset stays private to avoid contaminating future AI training, but a smaller public version is available for testing.
Even with these low scores, Safar sees some hope: the best models do better than chance and show basic visual reasoning skills. Whether those skills can be improved by scaling up existing methods, or if new approaches are needed, is still an open question.
A year ago, a Chinese study found similar weaknesses in multimodal language models, but with much higher results. Back then, GPT-4o managed 54.8 percent accuracy on dashboard tasks that included reading clocks and gauges. The current top score of 13.3 percent on ClockBench shows this new benchmark is much harder—and that AI clock-reading skills haven’t improved much either.