ARTICLE AD BOX
The research team at Hugging Face has introduced SmolLM2, their latest language model. While it doesn't break new ground, it represents a solid addition to the company's AI portfolio.
The model's effectiveness comes from carefully combining different sources for its 11 trillion token dataset and using a methodical training approach. The team started with a balanced mix of web content and programming examples, later adding specialized datasets for mathematics and coding tasks.
The researchers evaluated the model's performance after each training phase to identify gaps, then adjusted the training data accordingly. They created custom datasets including FineMath for complex mathematical problems, Stack-Edu for well-documented code, and SmolTalk for conversation-related tasks.
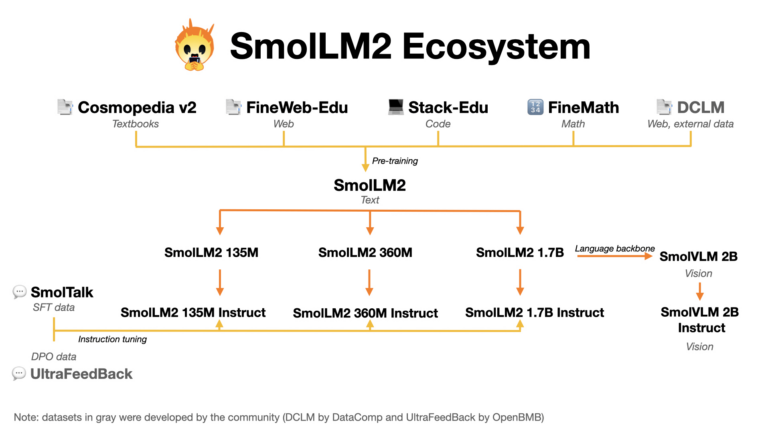 Hugging Face has developed its own data sets for the SmolLM2 models and makes them available as open source. | Image: Hugging Face
Hugging Face has developed its own data sets for the SmolLM2 models and makes them available as open source. | Image: Hugging FaceAfter initial training, the team refined SmolLM2 through instruction fine-tuning and example-based learning to improve its task comprehension. They used reinforcement learning to help the model generate more user-aligned responses.
Ad
THE DECODER Newsletter
The most important AI news straight to your inbox.
✓ Weekly
✓ Free
✓ Cancel at any time
Competitive results show promise for specific use cases
In knowledge and comprehension benchmarks, SmolLM2 performs better than similar-sized models like Qwen2.5-1.5B and Llama3.2-1B in several areas, though not across the board.
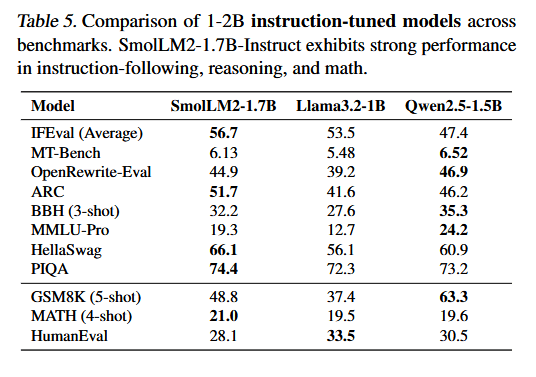 In many benchmarks, the hugging face model outperforms its Meta and Qwen competitors, but performs rather poorly in mathematical problem solving, for example. | Image: Hugging Face
In many benchmarks, the hugging face model outperforms its Meta and Qwen competitors, but performs rather poorly in mathematical problem solving, for example. | Image: Hugging FaceBesides the main 1.7 billion parameter version, the team developed two smaller variants with 360 and 135 million parameters, both showing solid results for their size.
Hugging Face has become essential to open-source AI development through its extensive model weight repository. The company aims to actively advance research rather than just store data for others.
The company, backed by Google, recently released an AI agent library and created an open-source alternative to OpenAI's Deep Research. SmolLM2 uses proven approaches for efficient language models through its high-quality data mix and multi-stage training. While it matches similar models from Meta and Qwen, its practical value likely lies in handling smaller tasks on devices with limited processing power, like smartphones.
This development seems like a natural step for Hugging Face as a major AI player. Unlike Meta and Qwen, which only share model weights, Hugging Face maintains a complete open-source approach, making their training data available to everyone.
Recommendation