ARTICLE AD BOX
A new international study highlights major problems with large language model (LLM) benchmarks, showing that most current evaluation methods have serious flaws.
After reviewing 445 benchmark papers from top AI conferences, researchers found that nearly every benchmark has fundamental methodological issues.
"Almost all articles have weaknesses in at least one area," the authors write. Their review covered benchmark studies from leading machine learning and NLP conferences (ICML, ICLR, NeurIPS, ACL, NAACL, EMNLP) from 2018 to 2024, with input from 29 expert reviewers.
Benchmark validity is about whether a test truly measures what it claims. For LLMs, a valid benchmark means strong results actually reflect the skill being tested.
Ad
THE DECODER Newsletter
The most important AI news straight to your inbox.
✓ Weekly
✓ Free
✓ Cancel at any time
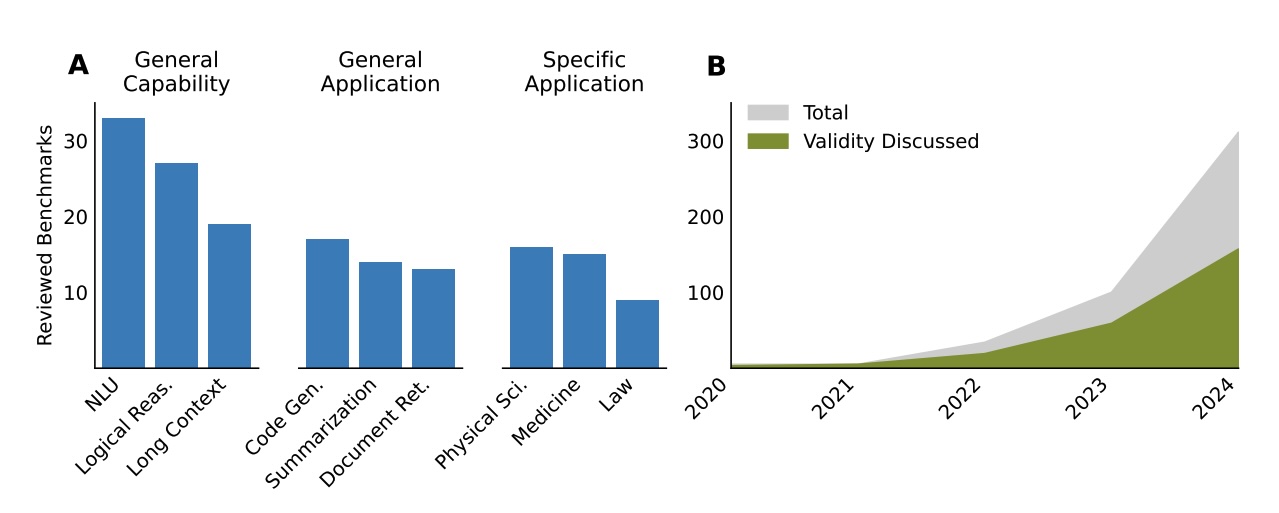 The most common benchmark categories (left) cover general capabilities, general applications, and specific applications. On the right, the number of benchmark publications and validity discussions has surged since 2020. | Image: Bean et al.
The most common benchmark categories (left) cover general capabilities, general applications, and specific applications. On the right, the number of benchmark publications and validity discussions has surged since 2020. | Image: Bean et al.Vague and inconsistent definitions undermine reliability
The study found that benchmark definitions are often unclear or disputed. While 78 percent of benchmarks define what they're measuring, almost half of those definitions are vague or controversial. Key terms like "reasoning," "alignment," and "security" are often left undefined, making conclusions unreliable.
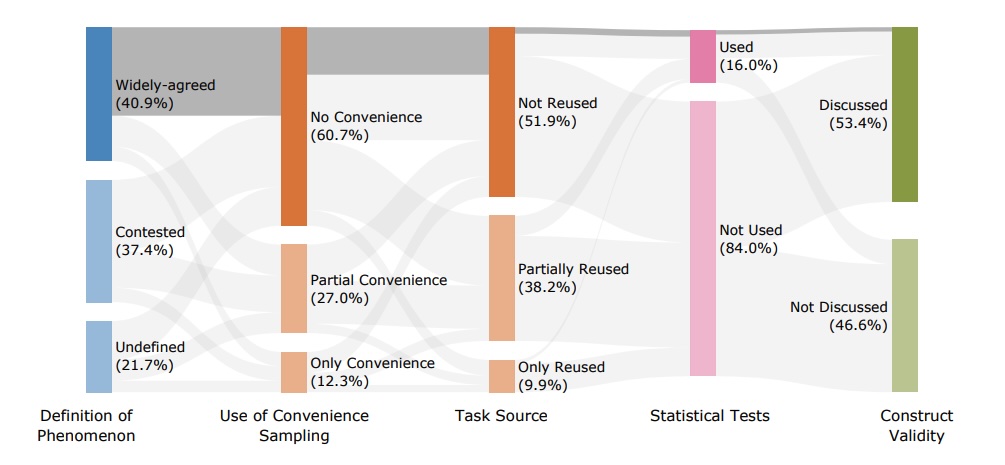 This diagram shows that very few benchmarks follow best practices for definition, sampling, data usage, statistical testing, and validity discussion. The shaded path marks the small group that meets all five standards. | Image: Bean et al.
This diagram shows that very few benchmarks follow best practices for definition, sampling, data usage, statistical testing, and validity discussion. The shaded path marks the small group that meets all five standards. | Image: Bean et al.About 61 percent of benchmarks test composite skills like agentic behavior, which combines recognizing intent and generating structured output. These sub-skills are rarely evaluated separately, making the results hard to interpret.
Another issue: 41 percent of benchmarks use artificial tasks, and 29 percent rely solely on them. Only about 10 percent use real-world tasks that actually reflect how these models are used in practice.
Poor sampling and recycled data undermine reliability
Sampling is another major weakness in current LLM benchmarks. About 39 percent rely on convenience sampling, and 12 percent use it exclusively, meaning they choose whatever data is easiest instead of data that truly reflects real-world use.
Data recycling is widespread, too. Around 38 percent of benchmarks reuse data from human tests or existing sources, and many rely even more heavily on datasets from other benchmarks.
Recommendation

This approach can distort results. For example, if a benchmark pulls math questions from a calculator-free exam, those numbers are chosen for simple arithmetic. Testing LLMs only on these types of problems won't reveal how models perform on more complex calculations.
Most benchmarks also lack strong statistical analysis. Over 80 percent use exact match scores, but only 16 percent apply statistical tests to compare models. The researchers argue that meaningful evaluations require robust statistics and clear uncertainty estimates.
Alternative methods are rare: just 17 percent use LLMs as judges, and only 13 percent rely on human judgment. Most benchmarks skip uncertainty estimates and statistical tests entirely, creating big gaps in reliability.
What better LLM benchmarks look like
The research team lays out a clear path forward: define exactly what each benchmark measures and set clear, specific boundaries. Benchmarks should focus only on the target skill, without distractions from unrelated tasks or confusing formats.
Dataset selection should be intentional, not just based on convenience. When reusing data, authors should disclose it and explain any limitations. To ensure fair comparisons, check whether test items appear in a model’s training data and keep hidden test sets secure.
Strong statistical methods and uncertainty estimates are essential for meaningful model comparisons. Finally, both quantitative and qualitative error analysis should be used to uncover patterns and recurring weaknesses.
The researchers point to GSM8K, a widely used math benchmark, as a case in point. They say GSM8K is intended to test math reasoning with grade-school arithmetic, but in practice, it mixes in reading comprehension and logic skills without evaluating them separately.
They also argue that proper contamination testing - checking if test items overlap with a model’s training data - could have prevented some reported performance gains. A more thorough error analysis would make the benchmark more useful.
The recent Llama 4 controversy is another warning sign. Meta's new models performed well on user benchmarks at first, although they failed badly on long-context tasks. Meta later admitted to using a specially tuned chat version for the LMArena benchmark, optimized for human judges, highlighting how easily benchmark results can be manipulated.
Even with their flaws, benchmarks remain the backbone of AI research. They provide the structure for tracking model progress and comparing different approaches. But as LLMs grow more complex and the stakes get higher, the risks of weak or misleading benchmarks also increase. Without tougher standards and full transparency, it's impossible to separate real advances from results that simply game the tests.


