ARTICLE AD BOX
ARC-AGI-3 aims to test how well AI systems can handle brand new problems. While people breeze through the challenges, the latest AI models still come up short.
AI researcher François Chollet and his team have released ARC-AGI-3, the latest version of their benchmark for evaluating general intelligence. According to Chollet, ARC-AGI-3 is built to measure whether AI systems can learn on their own in truly unfamiliar situations, without any background knowledge or hints. The tasks draw only on so-called "core knowledge priors" - basic cognitive abilities like object permanence and causality - and leave out language, trivia, and cultural symbols entirely.
The "Developer Preview" offers three interactive test games that, according to the creators and the leaderboard, humans can solve quickly and easily. So far, AI systems have consistently failed to beat any of the games, except for one entry with unknown origins.
OpenAI researcher Zhiqing Sun claims on X that the new ChatGPT agent can already solve the first game, but it's unclear whether OpenAI's agent is actually the one holding the top spot.
Ad
THE DECODER Newsletter
The most important AI news straight to your inbox.
✓ Weekly
✓ Free
✓ Cancel at any time
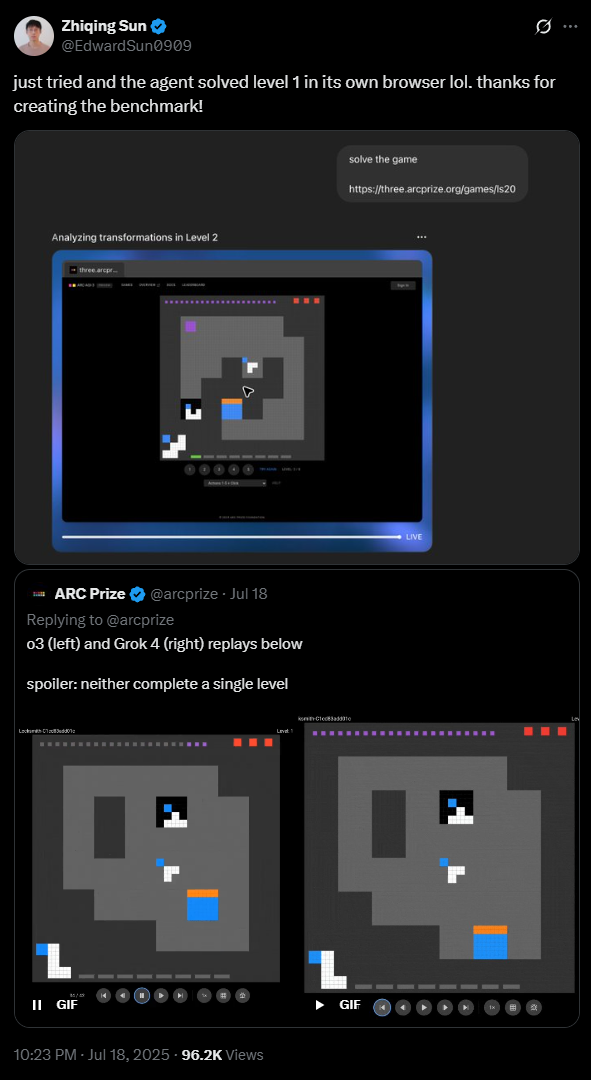 Image: via X
Image: via XInteractive games replace static tests
The big change in ARC-AGI-3 is its interactive format. Instead of static problems, the new version features mini-games set in a grid world. To win, AI agents have to figure out the rules and objectives for themselves, learning how to succeed through trial and error.
The developers say this setup is meant to mirror how humans learn: by exploring, planning, and adapting to new environments - skills that remain mostly unreachable for today's AI systems. "As long as that gap remains, we do not have AGI," the project team writes on arcprize.org.
To go along with the preview, HuggingFace is sponsoring a sprint competition with a $10,000 prize. Participants have four weeks to build and submit the best-performing agent using the provided API.
By early 2026, the full benchmark is supposed to feature about a hundred different games, split into public and private test sets. More details about the benchmark, how to participate, and the API are available at arcprize.org.
