ARTICLE AD BOX
Researchers at Sakana AI have introduced Text-to-LoRA (T2L), a method that adapts large language models to new tasks using only a simple text description - no extra training data required.
Large language models typically get specialized using techniques like LoRA (Low-Rank Adaptation). LoRA works by inserting small, low-rank matrices into certain layers of the model, making the adaptation process much more efficient than full fine-tuning. Instead of updating billions of parameters, only a few million need adjustment.
Still, each new task usually requires its own training data and carefully tuned hyperparameters, making the process time-consuming and resource-intensive. Text-to-LoRA automates this step. The system uses a hypernetwork trained on 479 tasks from the Super Natural Instructions Dataset. By learning to connect task descriptions to the right LoRA settings, T2L can generate LoRA weights for a new task in just one step - even if it has never seen the task before.
Video: Sakana AI
Ad
THE DECODER Newsletter
The most important AI news straight to your inbox.
✓ Weekly
✓ Free
✓ Cancel at any time
Sakana AI developed three T2L variants: T2L-L (55 million parameters) generates both LoRA matrices at once, T2L-M (34 million parameters) shares an output layer for both, and T2L-S (5 million parameters) generates only individual matrix ranks.
The team compared two training approaches for T2L: reconstruction training, where the system learns to recreate existing LoRA adapters, and supervised fine-tuning (SFT), where it's trained directly on target tasks.
SFT models outperformed reconstruction-based ones, achieving 66.3 percent of the reference benchmark on average versus 61.8 percent. The researchers attribute this to SFT's ability to group similar tasks more effectively.
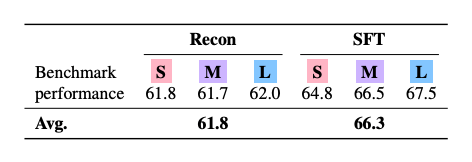 T2L models trained with supervised fine-tuning achieve higher average zero-shot performance. | Image: Sakana AI
T2L models trained with supervised fine-tuning achieve higher average zero-shot performance. | Image: Sakana AIIn tests on ten standard benchmarks, the best T2L model reached 67.7 percent average performance. In a direct comparison on eight benchmarks, T2L scored 74.0 percent, just behind task-specific LoRA adapters at 75.8 percent - about 98 percent of the reference performance, but without any additional training effort.
Adapting to unseen tasks
T2L can handle entirely new tasks, outperforming multi-task LoRA baselines and other methods. Performance, however, hinges on how closely the new task matches the training data - the closer the fit, the better the outcome.
Recommendation

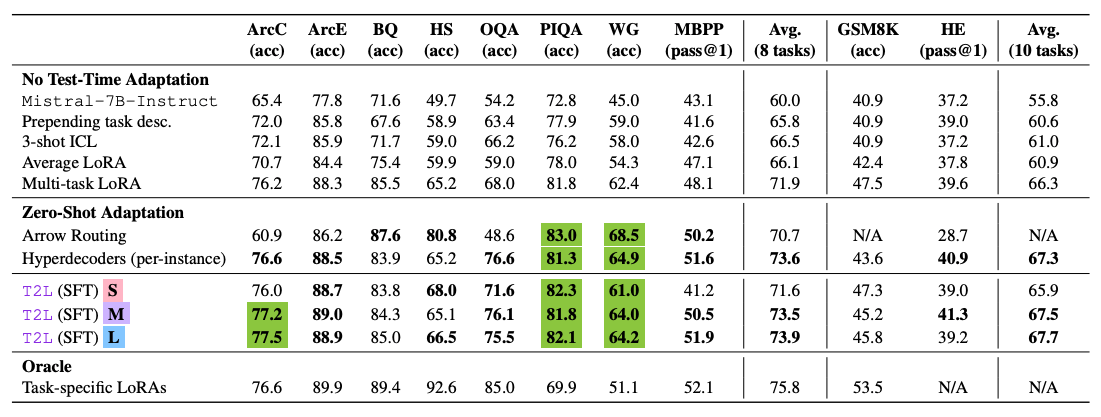 Zero-shot performance of text-to-LoRA (S/M/L) compared to baselines on ten benchmarks; values marked in green above the task-specific LoRAs, in bold those above the multi-task LoRA. | Image: Sakana AI
Zero-shot performance of text-to-LoRA (S/M/L) compared to baselines on ten benchmarks; values marked in green above the task-specific LoRAs, in bold those above the multi-task LoRA. | Image: Sakana AIClear, task-focused prompts deliver results comparable to specialized adapters, while vague descriptions hurt performance.
 Precise, task-specific descriptions with T2L LoRAs on Mistral-7B produce correct GSM8K answers through different calculation paths, while generic prompts lead to errors. This highlights T2L's level of controllability. | Image: Sakana AI
Precise, task-specific descriptions with T2L LoRAs on Mistral-7B produce correct GSM8K answers through different calculation paths, while generic prompts lead to errors. This highlights T2L's level of controllability. | Image: Sakana AIAccording to the study, T2L is highly efficient, requiring over four times fewer computational operations than classic fine-tuning and no task-specific training data. It also worked reliably with models like Llama-3.1-8B and Gemma-2-2B.
Limitations remain: T2L is sensitive to prompt wording and still trails specialized LoRA adapters on complex, out-of-distribution tasks. Still, the researchers see it as a strong step toward automated model adaptation. The code and installation instructions are available on GitHub.
