ARTICLE AD BOX
A new AI framework called SwiReasoning is designed to help large language models reason more efficiently.
Developed by researchers at Georgia Tech and Microsoft, SwiReasoning automatically switches between different reasoning strategies to improve both accuracy and token usage. At its core, SwiReasoning toggles between two reasoning modes: chain-of-thought and latent reasoning. Chain-of-thought handles problems step by step in plain language, while latent reasoning takes place inside the model’s vector space, without explicit text output.
Video: Shi et al.
SwiReasoning decides when to switch modes by measuring the model’s uncertainty using the entropy of token probabilities. Low entropy signals the model is confident, while high entropy means it is unsure.
Ad
THE DECODER Newsletter
The most important AI news straight to your inbox.
✓ Weekly
✓ Free
✓ Cancel at any time
If uncertainty drops, the framework shifts into explicit mode to solidify its current line of thought. If uncertainty rises, it moves back into latent mode to test alternative solutions. To prevent rapid back-and-forth switching, SwiReasoning uses asymmetric dwell times: switching to explicit mode happens instantly, but returning to latent mode requires a minimum number of steps.
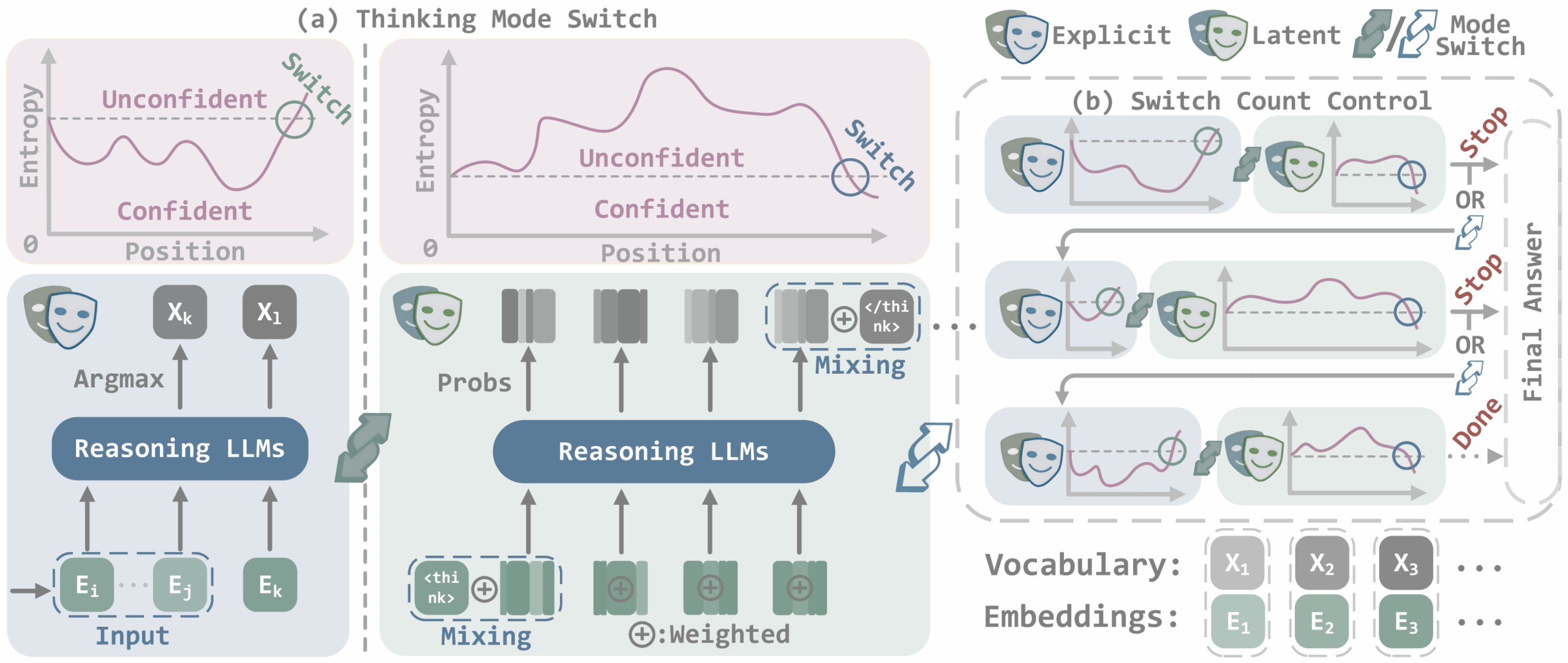 SwiReasoning automatically switches between explicit and latent reasoning based on the model’s uncertainty. A switch count mechanism limits mode changes to prevent overthinking. | Image: Shi et al.
SwiReasoning automatically switches between explicit and latent reasoning based on the model’s uncertainty. A switch count mechanism limits mode changes to prevent overthinking. | Image: Shi et al.To keep models from getting stuck in endless cycles of internal debate, SwiReasoning caps the number of allowed mode switches. When the model reaches half the limit, it gets a prompt to wrap up its reasoning. If it exceeds the maximum, the system forces an immediate response. This stops the model from wasting tokens on unproductive thought loops, so-called overthinking.
Slight improvements on tough tasks
The team tested SwiReasoning on three smaller models under ten billion parameters: Qwen3-8B, Qwen3-1.7B, and a distilled Deepseek R1 with eight billion parameters. They ran these models through five benchmarks covering math and science questions, from elementary problems to graduate-level tasks.
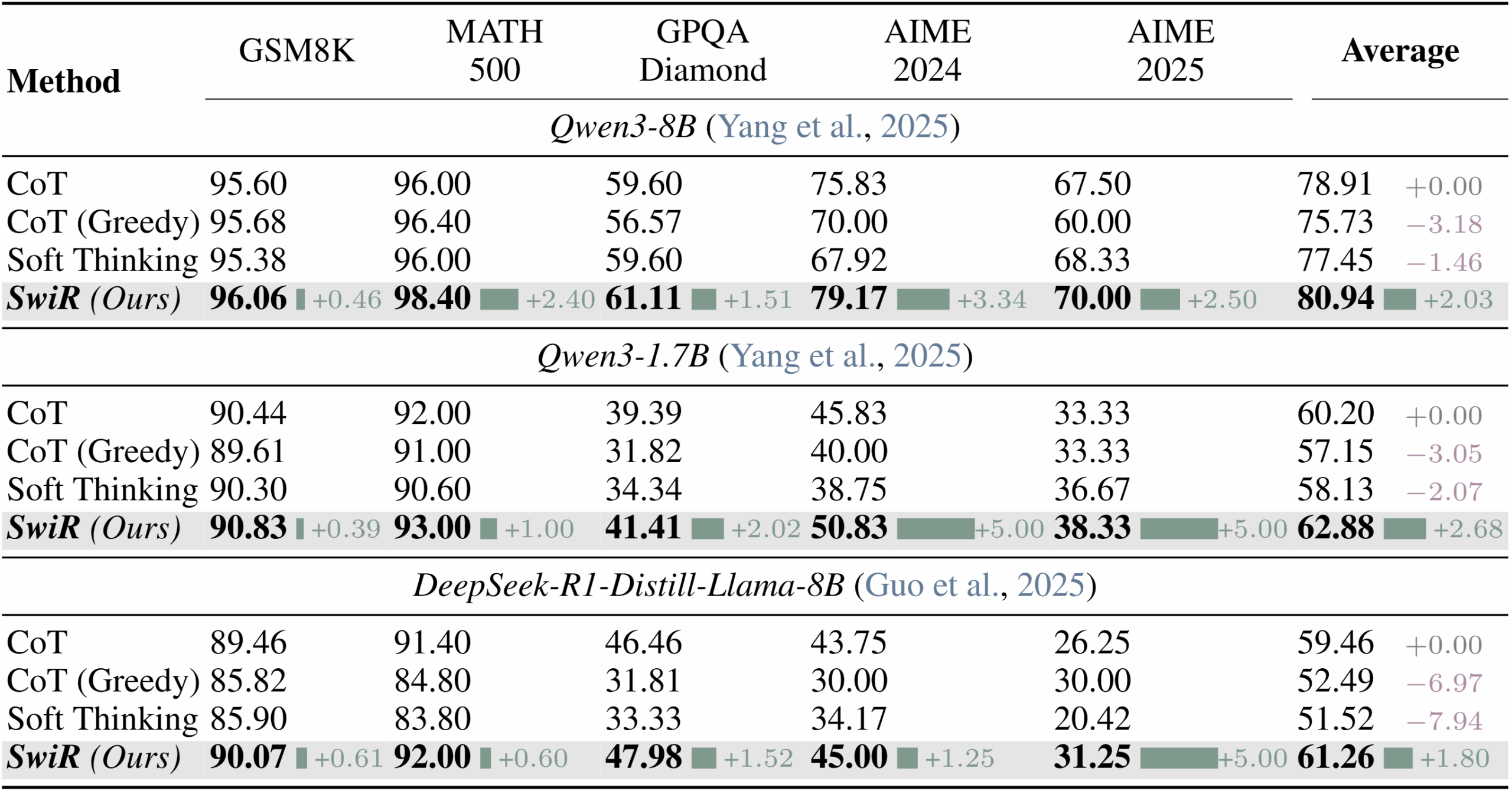 Across three models, SwiReasoning raised average accuracy by 2.17 percentage points. | Image: Shi et al.
Across three models, SwiReasoning raised average accuracy by 2.17 percentage points. | Image: Shi et al.Without token limits, SwiReasoning improved accuracy by up to 2.8 percent on math and 2 percent on science tasks, with the biggest jumps on the hardest problems. The researchers say adaptive switching between reasoning modes is most effective for complex problems that require long reasoning chains.
Higher token efficiency
SwiReasoning’s benefits grow under strict token constraints. In these tests, the framework improved token efficiency—meaning accuracy per token spent—by 56 to 79 percent, and in some cases by as much as 6.8 times compared to standard chain-of-thought. Higher token efficiency lets models get better results with less compute.
Recommendation
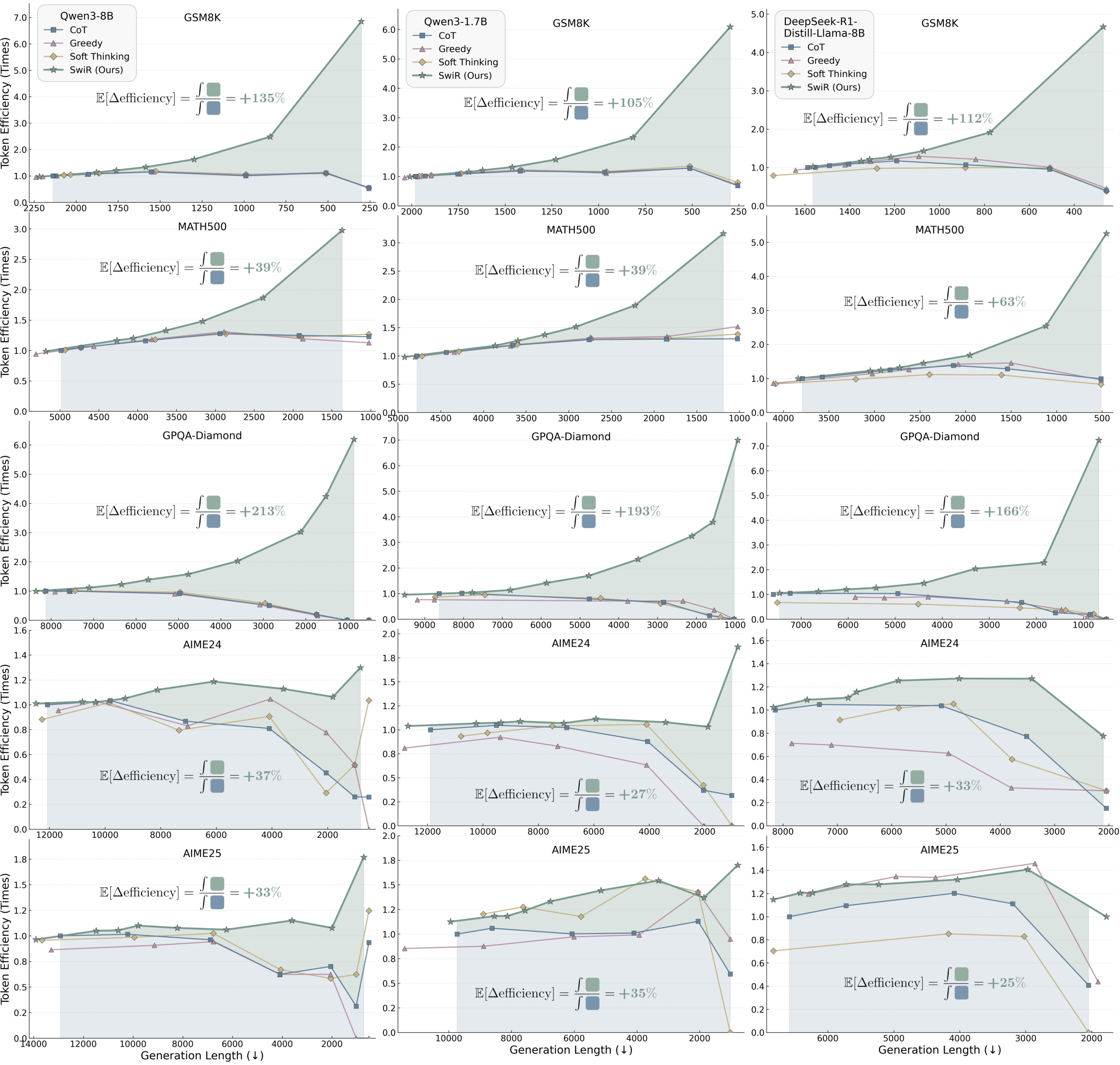 SwiReasoning (green line) consistently outperforms standard Chain-of-Thought, Greedy Decoding, and Soft Thinking at different token budgets. | Image: Shi et al.
SwiReasoning (green line) consistently outperforms standard Chain-of-Thought, Greedy Decoding, and Soft Thinking at different token budgets. | Image: Shi et al.In multi-attempt experiments, SwiReasoning often needed far fewer tries to hit maximum accuracy. In one case, it found the right answer in just 13 attempts instead of 46, cutting the number of tries by 72 percent.
SwiReasoning requires no extra training and can be dropped in as a replacement for standard generation functions without changing the model’s architecture or parameters. The implementation is available on GitHub and can be used alongside other efficiency methods like memory optimization or faster decoding.