ARTICLE AD BOX
Anthropic sees growing potential for language models in cybersecurity. The company cites results from the CyberGym leaderboard: Claude Sonnet 4 uncovers new software vulnerabilities about 2 percent of the time, while Sonnet 4.5 increases that rate to 5 percent. In repeated tests, Sonnet 4.5 finds new vulnerabilities in more than a third of projects.
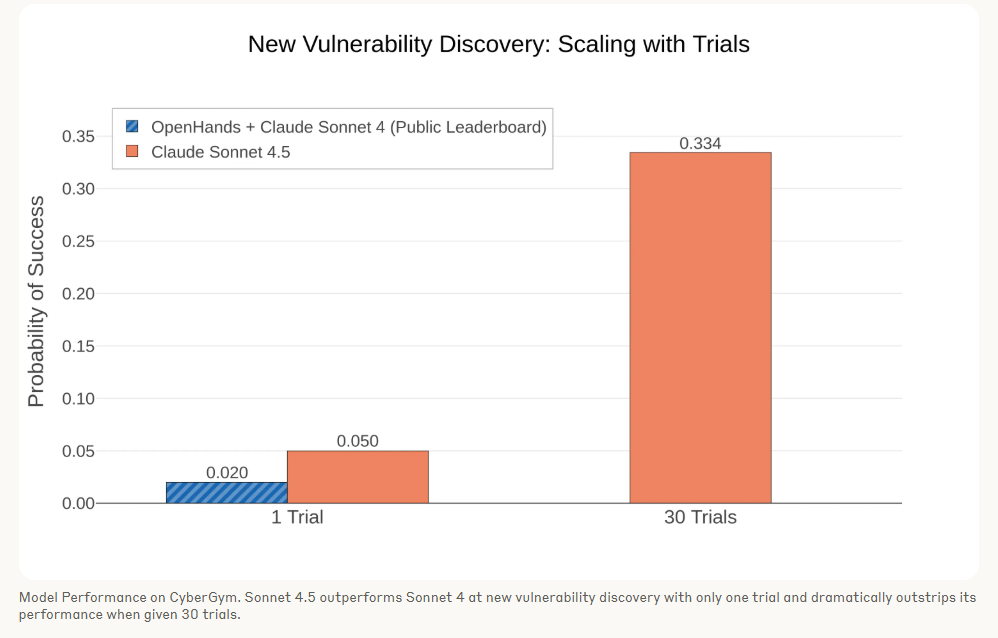 Image: Anthropic
Image: AnthropicIn a recent DARPA AI Cyber Challenge, Anthropic notes that teams used large language models like Claude "to build 'cyber reasoning systems' that examined millions of lines of code for vulnerabilities to patch." Anthropic calls this a possible "inflection point for AI’s impact on cybersecurity."